You Might Consider Using an Image Sitemap
Depending on the site, image sitemaps can be a helpful tool in an SEO strategy, making it ultra-clear to search engines the images they can and should index. Let's explore setting one up.Despite not being strictly necessary for every site, sitemaps are still an important piece of a solid SEO game, allowing search engines to crawl & index your website’s content more quickly and thoroughly (especially if your site is large, new, or poorly linked).
But they’re not just useful for text content. Image sitemaps serve a similar purpose, specifically geared toward images (obvi). You've very likely accessed content made discoverable through one of them. If you've ever used Google Images, for example, an image sitemap might deserve some credit.
Who Needs Them?
Search engines can crawl images just fine via <img> tags in your HTML (in fact, most of the sites I've been perusing don't have one). But if imagery is a core content type on your website, it’s probably a good idea to set one up. I'm thinking of sites in categories like these:
- family, & portrait photography
- e-commerce
- stock photography
- art/illustration
But even aside from that, you might benefit from an image sitemap if you’re rendering images with client-side JavaScript or single-page application. Opting out of server-rendered HTML makes it more slower and more difficult for Google to index this content (although they allegedly do so), so it's in your best interest to explicitly serve them to Google.
How to Create an Image Sitemap
The structure of an image sitemap is simple — a list of page URLs with images nested beneath each. Generating one requires you to know where the images in your content live, and then spitting out some XML. Here's how that structure looks:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:image="http://www.google.com/schemas/sitemap-image/1.1">
<url>
<loc>https://ur-site.com/first</loc>
<image:image>
<image:loc>https://ur-site.com/img1.jpeg</image:loc>
</image:image>
<image:image>
<image:loc>https://ur-site.com/img2.jpeg</image:loc>
</image:image>
</url>
<url>
<loc>https://ur-site.com/second</loc>
<image:image>
<image:loc>https://ur-site.com/img3.png</image:loc>
</image:image>
</url>
</urlset>Serve that output with a application/xml "Content-Type" and you have a valid image sitemap, ready for use by search engines.
Doing It Programmatically
Of course, if you're working with CMS of any sort and have regularly changing content, you'll want this automated. Some frameworks make it easier than others. Keep in mind: all the code you're about to see is for scrappy, demonstration purposes. So, maybe don't just slap it into your system. Or code review it.
Example: WordPress
With WordPress, you can generate a simple image sitemap by querying for all of the images attached to each page, and then echoing XML to the client. A rudimentary version doesn't take that much code. All the following example does is loop through each published post, extract all <img> tags (I was having trouble with get_attached_media()), and piece together the sitemap.
<?php
add_action('template_redirect', function () {
if (explode('?', $_SERVER['REQUEST_URI'])[0] !== '/image-sitemap') {
return;
}
$posts = get_posts([
'post_type' => 'post',
'posts_per_page' => -1,
'post_status' => 'publish',
]);
$sitemapContent = "";
foreach ($posts as $post) {
$permalink = get_permalink($post->ID);
$document = new DOMDocument();
libxml_use_internal_errors(true);
$document->loadHTML($post->post_content);
$images = $document->getElementsByTagName('img');
libxml_use_internal_errors(false);
foreach ($images as $image) {
$imageUrl = $image->getAttribute('src');
$sitemapContent .= "<url>
<loc>$permalink</loc>
<image:image>
<image:loc>$imageUrl</image:loc>
</image:image>
</url>";
}
}
header('Content-Type: application/xml; charset=utf-8');
echo "<?xml version='1.0' encoding='UTF-8'?>
<urlset
xmlns='http://www.sitemaps.org/schemas/sitemap/0.9'
xmlns:image='http://www.google.com/schemas/sitemap-image/1.1'
>$sitemapContent</urlset>";
die();
});With that in your theme (or wrapped up in plugin), an image sitemap would live at https://ur-site.com/image-sitemap without any other admin work. Just run with it.
Example: Statamic
If you're working with something like Statamic, it feels a little more elegant. Query for published posts, identify the images, and ship it.
<?php
use Illuminate\Support\Facades\Route;
use Statamic\Facades\Entry;
Route::get('/image-sitemap', function () {
$entries = Entry::query()
->where('collection', 'posts')
->where('published', true)
->limit(5)
->get();
$sitemapContent = $entries->reduce(function ($carry, $entry) {
$document = new DOMDocument();
$document->loadHTML($entry->content);
return $carry . collect($document->getElementsByTagName('img'))->reduce(function ($carry, $image) use ($entry) {
$imageUrl = $image->getAttribute('src');
return $carry . "<url>
<loc>https://ur-site.com/posts/{$entry->slug}</loc>
<image:image>
<image:loc>$imageUrl</image:loc>
</image:image>
</url>";
}, '');
}, '');
return response("<urlset xmlns='http://www.sitemaps.org/schemas/sitemap/0.9'
xmlns:image='http://www.google.com/schemas/sitemap-image/1.1'>
$sitemapContent
</urlset>")->header('Content-Type', 'application/xml');
});The biggest reason I'm including that example, by the way, is because I've been dabbling in the framework and really like it.
Example: Astro
The framework I build my own sites on, Astro, makes it easy enough as well using a custom endpoint. Create a pages/image-sitemap.xml.js file, and from there on, it's a similar story:
import { getCollection } from "astro:content";
export async function GET(context) {
const posts = await getCollection("blog");
const sitemapContent = posts.reduce((acc, post) => {
const images = posts
.map((post) => {
const images = post.body.match(/!\[.*?\]\((.*?)\)/g);
return images?.map((image) => image.match(/\((.*?)\)/)[1]) || [];
})
.flat()
.map((image) => {
// If the image is a relative path, prepend the site URL.
if (image.startsWith("/")) {
return image.replace("/", "https://ur-site.com/");
}
return image;
});
return `${acc}
<url>
<loc>https://ur-site.com/${post.slug}</loc>
${images.reduce((acc, image) => {
return `${acc}
<image:image>
<image:loc>${image}</image:loc>
</image:image>
`;
}, "")}
</url>`;
}, "");
return new Response(
`<?xml version="1.0" encoding="UTF-8"?>
<urlset
xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:image="http://www.google.com/schemas/sitemap-image/1.1"
>
${sitemapContent}
</urlset>`,
{
headers: {
"Content-Type": "application/xml",
},
});
}Of course, this example assumes your posts are written in Markdown. If you're using any sort of headless solution, you'd likely want to reach for an HTML parsing solution like earlier (JSDOM will do the job just fine).
Or, to make it even easier...
If you don't want to expend the time and mental energy building an image sitemap yourself, there's another option: let PicPerf do it for you. As it's optimizing & caching the bananas out of your images, it'll be constantly building a dynamically updated image sitemap.
If you go this route, there are two steps:
First, tag your image URLs with an sitemap_path query parameter, with the value bring the current page path:
<img alt="me" src="https://ur-site.com/my-image.jpg?sitemap_path=/about">The WordPress, Statamic, and Astro integrations will also handle this for you.
Second, proxy that sitemap through your own domain (Google won't accept sitemaps that live on non-verified domains). Depending on how your site is built, there are several approaches to this that aren't complicated. And eventually, integrations will set it it all up on your site automatically.
Wiring Up Your Sitemap
Once that endpoint is live, you've got two remaining tasks:
First, you'll need to reference it in your robots.txt file. It's very simple bit of content, and even supports pointing to multiple sitemaps:
User-agent: *
Allow: /
Sitemap: https://ur-site.com./page-sitemap.xml
Sitemap: https://ur-site.com./image-sitemap.xmlYou could go the route of using a <link rel="sitemap"> tag in your HTML, but using the robots.txt file is the most widely used convention, and probably the safer bet if you want maximum compatibility with web crawlers (that said, it likely wouldn't hurt to use both approaches).
Finally, add it to Google Search Console. Providing the sitemap URL to Google directly is useful for catching validation errors, and it gives you some insight into the indexing performance of the sitemaps you submit.
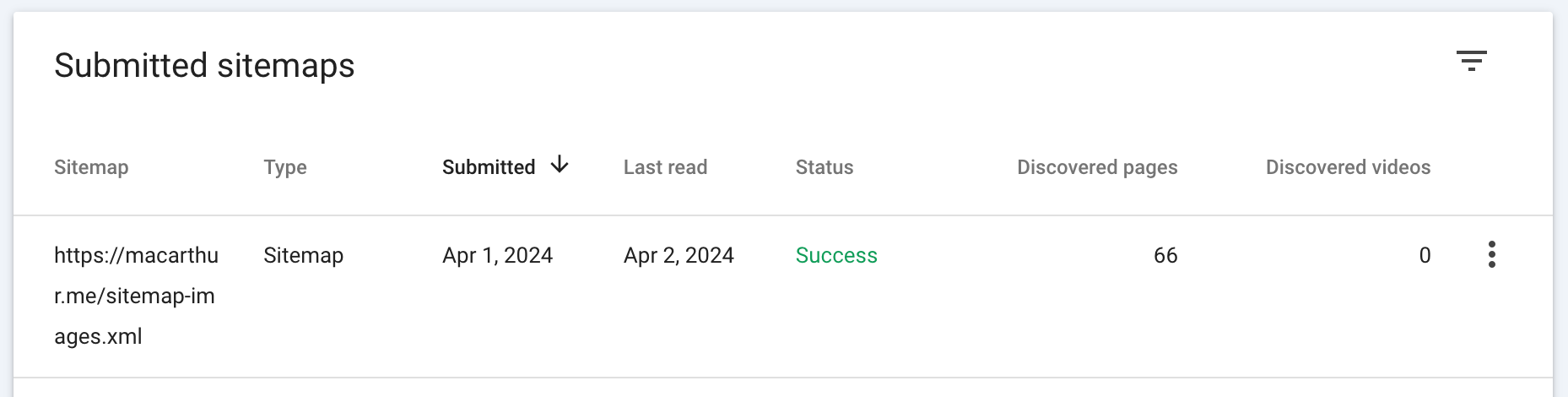
Even though it'll be accessible to crawlers via your robots.txt file, submitting it directly to Google should also help expedite its indexing, giving that extra "hint" in accessing as much of your site's content as possible.
Turn Over Every Stone
Google and other engines are really good at finding, crawling, and indexing content. Even if you run an image-centric site and totally disregard everything you see here, you have little reason to lose any sleep.
But enabling engines to crawl any your content isn't really the final aim of a sitemap. It's about giving engines that extra bit of intentional clarity into what's available and should be crawled. It allows you to leave no doubt that your content will be seen; to proactively serve these entities rather than waiting around for them to get to you.
I can't promise it'll be a game-changer for your SEO strategy, but at least you'll leave one less stone unturned.
Ready to upgrade your site's image performance?